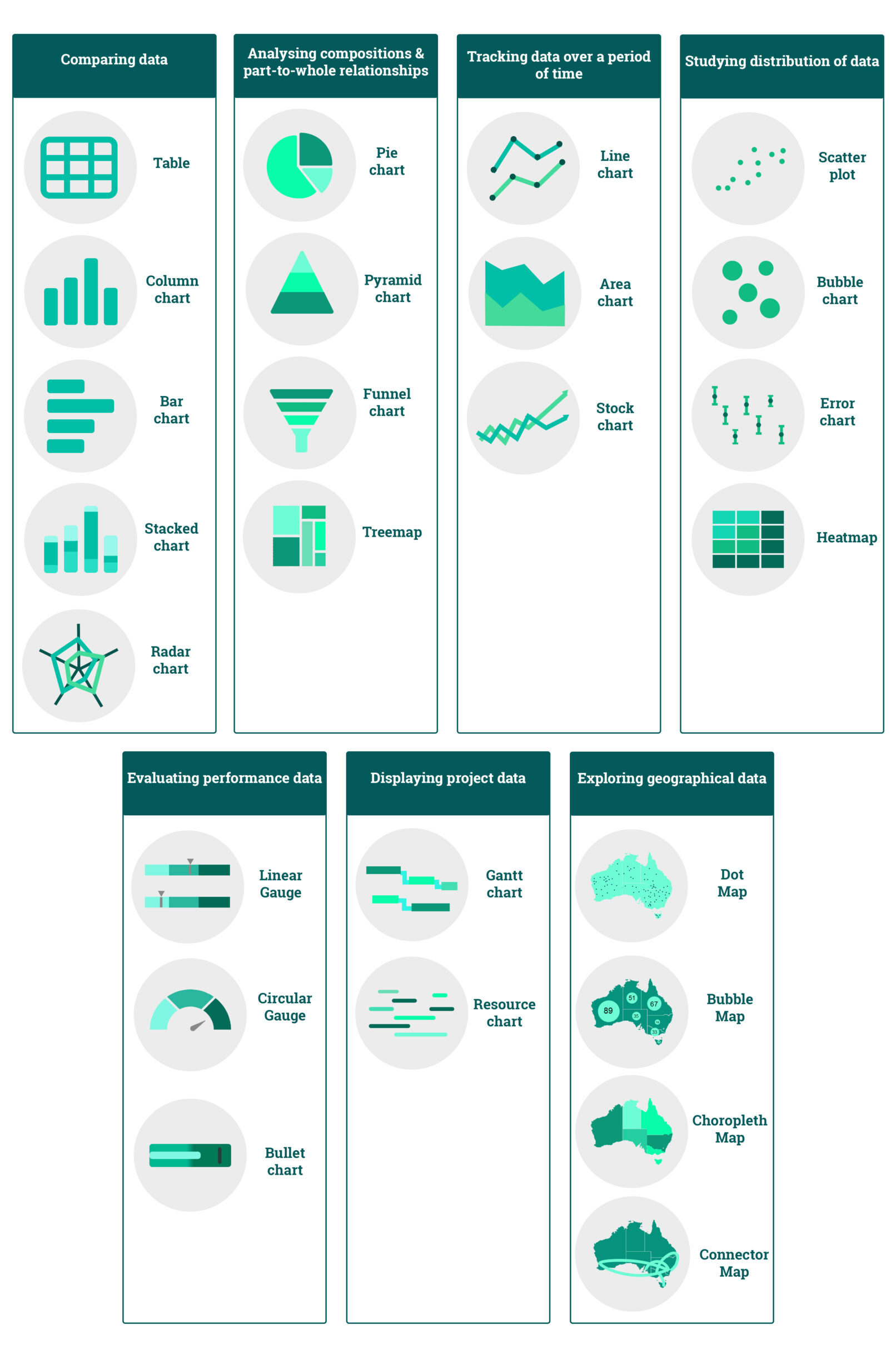
Cheatsheet for Charts: Pair the Right Chart with the Right Set of Data
To ensure your message conveyed through your data is clear and correct, you need to use the right charts to visualize it.

To ensure your message conveyed through your data is clear and correct, you need to use the right charts to visualize it.

Whether you’re a business user newly learning SQL or a Data Analyst who is already a pro, it never hurts to keep a handy reference guide for a quick peek the next time you’re writing an SQL query!

Have you ever had trouble working with large datasets? Are you frustrated having to move large datasets from a data warehouse to the workstation that has your analytical tools? Are you still using slow ODBC/JDBC connectors? You need to consider using modern data analytics tools with in-database query capabilities.

