As more and more enterprises started looking at various ways to support their data-driven initiatives, data consolidation and storage solutions have been getting a lot of attention. Data warehouses, data lakes, data virtualization, and data marts are all popularly used approaches to data integration and storage. While analysts and data experts are familiar with these terms, many don’t understand the differences and use them interchangeably. Even though they all have similar core functions, it’s essential to understand the differences between them to find the right approach that fits your organization’s data needs.
Data Mart, Lake, Warehouse, and Virtualization: What’s the Difference and which one to choose?
July 19, 2020 | Article
What are Data Warehouses?
Data warehouses are central repositories of consolidated and structured data from one or multiple data sources, loaded using the ETL process. Also known as enterprise data warehouses, they deal with data that has been uploaded directly from the operational systems of a business and are mainly used for reporting and data analysis. Examples of traditional data warehouses are Teradata and Netezza, while Snowflake and Redshift are modern cloud-based SaaS versions.

They are the best option when:
- Data is highly structured and well-defined
- Warehouse’s purpose is also well-defined
- The objective is to run fast SQL queries
- There are no challenges with data integration
What are Data Marts?
A data mart is a subsection of the data warehouse that focuses on information from a specific subject or department, tailored to fit the objective of a particular set of users without redundancy. To put it simply, if a data warehouse is like a library, then data marts are like individual sections that pertain to different topics. They provide subject-oriented summarized data derived from the data warehouse and can help avoid one department interfering with another department’s data.
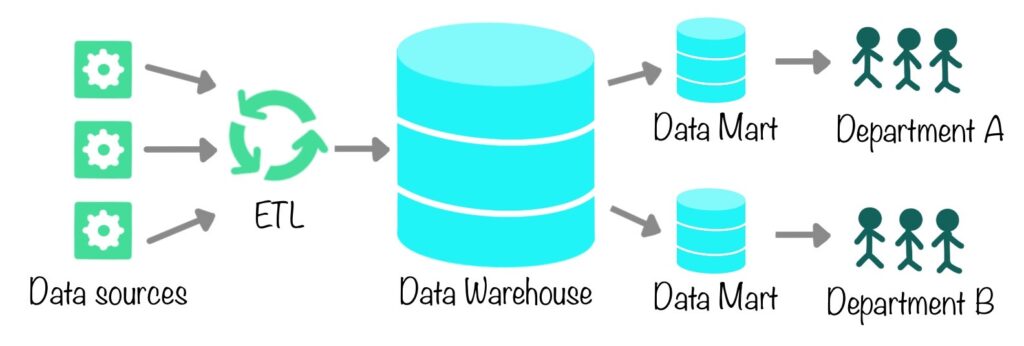
They are the best option when you need:
- To ease the query workload on the data warehouse
- A place for data mining
- To change the data to simulate some business scenarios without affecting the core warehouse
- To create a static copy of a few tables for analysis or reporting purposes
What is Data Virtualization?
Data virtualization is the method of aggregating data from disparate sources to develop a unified virtual view of information independent from its physical location or format in real-time. It enables businesses to view, access, manage, and analyze data without the need to know its location. The data virtualization approach involves creating a virtual layer to allow access, manipulation, and transformation of data in virtual views, which is simpler and more time-efficient. Companies such as Tibco, SAS, Denodo, and Cambridge Semantics offer stand-alone data virtualization solutions. In contrast, others, including Oracle, SAP, Microsoft, and Informatica, embed it as a feature of their top products.

They are the best option when:
- Quick deployment is required without much infrastructure
- Data teams need to run ad-hoc SQL queries on top of non-relational data sources
- Certain analytics use cases are present that may not require the robustness of a data hub
What are Data Lakes?
Data lakes are repositories that contain a large amount of raw data in its native format. They store data in an unorganized way, and there is no arrangement or hierarchy among the individual data assets. Just like real lakes that have multiple tributaries coming in, data lakes have unstructured, semi-structured, structured, and binary data flowing into them in real-time. Additionally, in data lakes, schemas are applied only when the data is ready to be used. The idea behind data lakes is to make any and all data readily available so that your data teams can get valuable business insights. Examples of companies that have data lake offerings include Hadoop, Cloudera, Amazon S3, and Microsoft Azure Data Lake.

They are the best option when you require:
- A low-cost alternative for storing massive amounts of data
- An inexpensive analytics sandbox
- Economical storage for machine learning projects’ training data
Share This Post
Find out how We can help with your Data-Driven Initiatives
